Simple Cybersecurity LLM Chatbot sorta [2024-03-18]
Posted on Mon 18 March 2024 in Thought
Why?
Because why not? I've already built a couple of LLM-specific focus bots that are truly locally hosted. But, documenting the process? That's new to me. Plus, I aimed for this to be a self-contained/isolated application. So, in this event, I wanted to document the basic setup since I am working in parallel on an LLM agent (more on that later). It's crucial to understand that these are chatbots, not co-pilots or assistants, as those, in my opinion, should be more LLM agent-focused. Or in other words, co-pilots/assistants can help decompose complex questions, attempt to draw conclusions, and resolve the question at play using readily available resources and tools.
Requirements
This needs to be able to run on a laptop and eventually be deployable to a cloud environment such as AWS (Elastic Beanstalk).
Laptop specs:
- Macbook Pro 14 inch
- Chip Apple M1 Max
- Memory 64 GB
- Storage 1TB
The Model of Choice
For the model of choice, I tested several. I normally would default to llama2 7b, 13B, or 70B chat, but for this application, I wanted to try something different that was more performant than llama2 13b and 70B, so I went with Mistral 7B v0.1. More can be read about comparing Mistral 7b to Meta's LLama2 7B/13B here.
Mistral final folder content:
- 14G tarball - mistral-7B-v0.1.tar
- 14G - consolidated.00.pth
- 484K - tokenizer.model
- 4.0K - params.json
- 14G - ggml-model-f16.gguf
- 4.1G - ggml-model-Q4_K_M.gguf (quantized to 4-bits)
Setup and Conversion
For the most part, one can just follow the steps from llama.cpp by ggerganov, which is inference of Meta's LLaMA models but supports several others.
Steps
Build llama.cpp:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
Add Mistral's 7B model to the './models' folder and extract it. It should look something like ./models/mistral-7B-v0.1.
Python virtual environment for model conversion:
Now, you will need to create a virtual environment to convert the model to ggml FP16 format, then quantize. The reasoning being it's better to isolate or contain this to a single environment rather than the broader system in case there are downstream dependency issues. For this, I experimented using UV by astral.sh. I wanted to try this Python package installer and resolver for better dependency management. Plus, it was written in Rust and a lot faster than the traditional pip manager.
You can download the UV install script or pip install uv. Once installed run the following commands:
uv venv
source .venv/bin/activate
uv pip install -requirements.txt
python convert_hf_to_gguf.py ./models/mistral-7B-v0.1/
./quantize ./models/mistral-7B-v0.1/ggml-model-f16.gguf ./models/mistral-7B-v0.1/ggml-model-Q4_K_M.gguf Q4_K_M
if everything went well you can test the model
# start inference on a gguf model
./llama-cli -m ./models/mistral-7B-v0.1/ggml-model-Q4_K_M.gguf -n 128
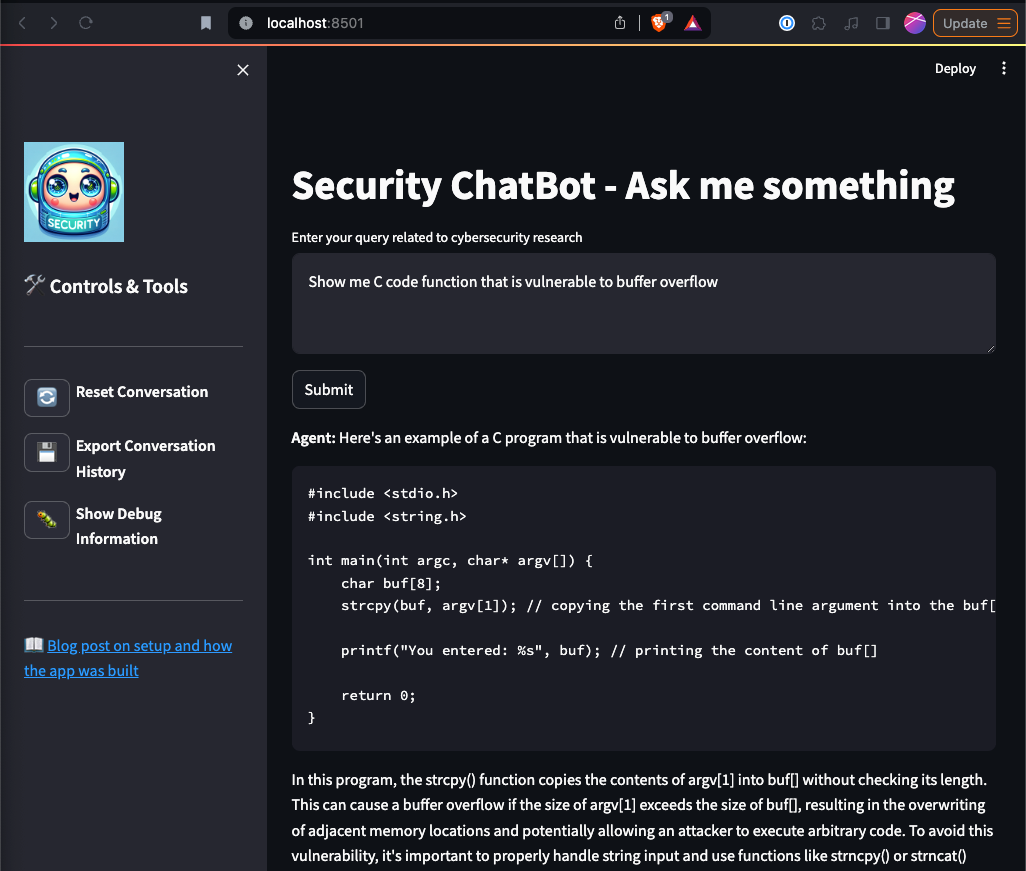
Streamlit App + LLM Chatbot
For this example, I decided to just whip up a simple chatbot to focus on security vulnerabilities. To do this, I load the Mistral model and create a specific prompt to ensure the bot focuses on the topics I care about.
The prompt (context)
I am focus on vulnerability related context or prompting. Feel free to change this to something you want to focus on when running the code.
The user is seeking in-depth analysis and actionable insights on cybersecurity vulnerabilities.
Please provide detailed information, potential mitigation strategies, and reference relevant tools or resources.
I have included the securitychat bot repository, which demostrates the follow features:
- Streamlit poc app
- Interactive chat interface
- Mistal 7B v1 model (self hosted)
- Conversation history
- Formatted code blocks
- Debugging information from model response
- Chat export
- Conversation reset
And all this in only 115 lines of code (LOC) at the time of the post
For this to be a true chatbot, it must have some memory or context through the conversation, but I'll save that for a later post with RAG and LLM agents functionality. For now, the conversation will just be stored in memory. So, if you refresh the application, all conversation will be lost. But luckily, we implemented Conversation export. If you want more chatbot functionality, check out Streamlit's Build a basic LLM Chat app
Running the app
Similar to the steps on setting up a venv mentioned earlier, prepare a workspace/working directory and create the venv along with installing streamlit and llama-cpp-python (binding to work with llama.cpp):
uv pip install streamlit llama-cpp-python
streamlit run app.py
Below is what the application will look like. Give it a go! Be sure to drop me a line at jay@stellerjay.pub if you have questions.